

 301-490-8439
301-490-8439 
Our Technology
Various Levels of Security
We understand that different applications call for different levels of security. That's why we offer three levels of voice masking protection.
- The SpeechMask® algorithm is a lower-cost method to implement a high-quality, speech-based sound mask ideal for most corporate customers. Layers of speech mixing and randomizing techniques are used to create a unique and highly effective mask.
- The M2 algorithm is a highly advanced speech-masking process using a natural-sounding voice spectrum for maximum effectiveness. Masking voices can be preloaded, or they can be sampled from the actual persons assigned to the room. The M2 algorithm is normally used to protect classified conversations taking place by personnel working in cleared contractor facilities. M2 is available to U.S. companies and NATO countries.
- Federal, state, and local government clients with a U.S. security clearance and Five Eyes countries can contact us for further voice masking options.

Soundmasking vs. SpeechMasking
Most soundmasking companies often use white or pink noise to create a wall of energy to implement their sound mask. Many companies even use unique digital noise-masking generators to create complex audio tracks. Some companies even design their masking generator to be soothing and acoustically friendly because they are pumping energy directly into a room or an open space. The problem occurs when a broadband mask is applied to cover up speech for security applications.
Unless they are used at uncomfortably loud levels, pink and white noises are not effective at masking the human voice — period. To effectively mask the human voice using a white noise generator, the power level from a white noise generator needs to be two to five times higher than the voice trying to be masked.
Additionally, broadband noises such a pink, white, and common digital soundmasking generators do not replicate or represent the human vocal system and can be filtered out by sophisticated speech extraction software. Human speech is primarily composed of energy having tonal characteristics (vowels) and other sounds with disruptive consonant characteristics (unvoiced plosives and fricatives). The turbulent airstream of voiced fricatives creates a chaotic mix of random frequencies that are completely different than those made by randomized white and pink noise generators. The sound of rushing water or a gentle hissing noise does nothing to effectively reduce intelligibility in the near field.
Another key feature to reducing intelligibility is the targeted use of reverberation and echo. Intelligibility tends to drop rapidly when speech become reverberant. There are at least 26 factors that affect intelligibility, and each factor must be accounted for in the process of making the absolute best speech mask available. Most important is how the mask is applied and directed inside the office space. In a properly designed speech-masking system for voice privacy, the occupants do not hear — or only faintly hear — the mask inside the room. The only way to listen to the mask is by listening directly against the outside wall. Then, and only then, will the speech mask present itself as vibrations and audible noise along the outside surface of the wall.
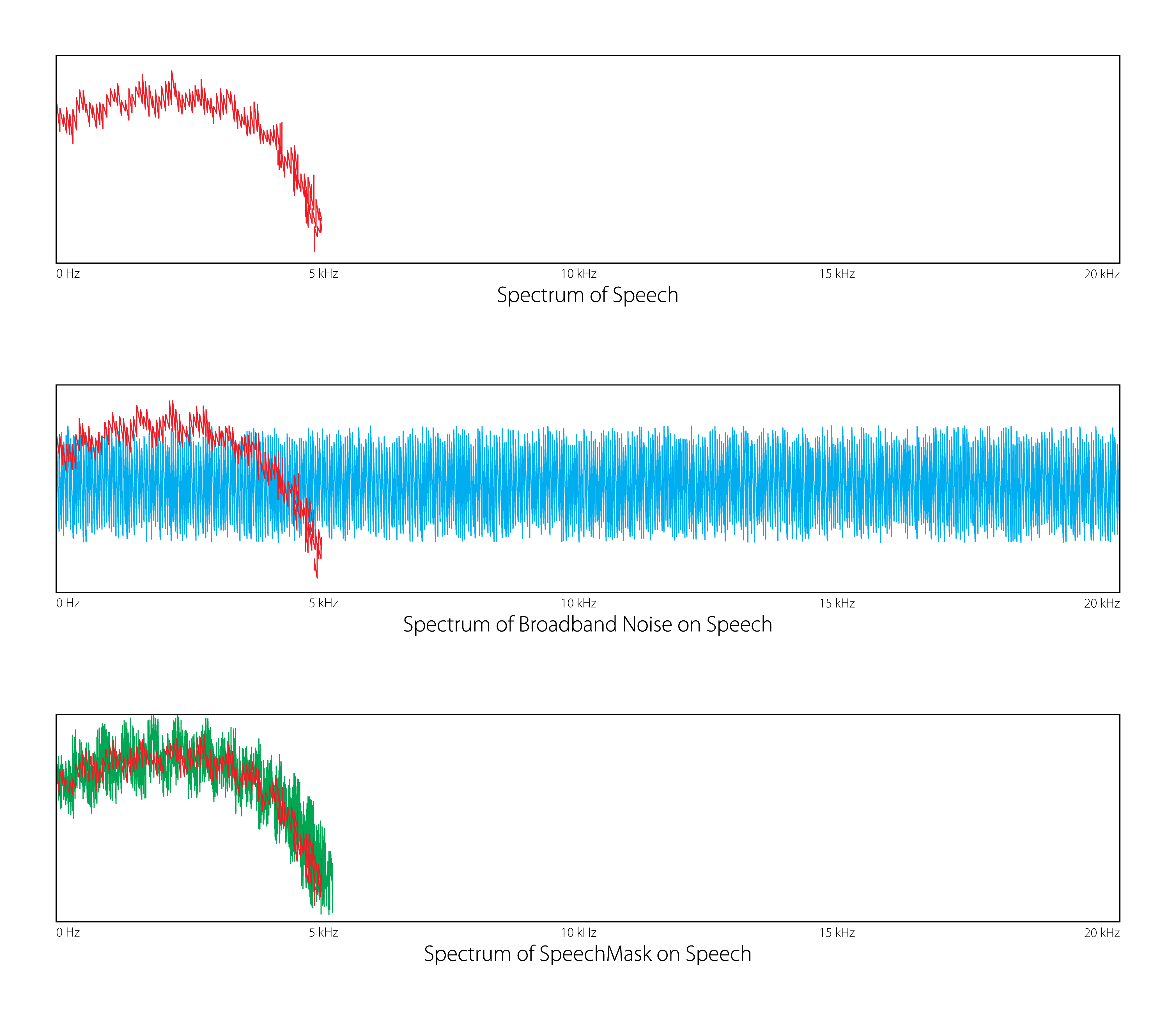
Representative figures show that the spectrum of SpeechMask® is much more suited to the actual qualities of human speech than broadband noise is.
Both SpeechMask® and our proprietary high-security M2 algorithm are available. The M2 algorithm is available to U.S. companies and NATO countries. In order to develop and create a truly effective masking device, our SpeechMask® technology was designed to focus acoustical energy where it is needed most to ensure voice privacy — directly inside the male and female voice spectrum. This creates a secure envelope of protection by targeting and generating only noises and speech created by the human vocal cords.
"The masking of speech depends on three characteristics of the masking sound. (1) Its intensity relative to the intensity of the speech, (2) its acoustic spectrum, and (3) its temporal continuity. The optimal masking noise must have a spectrum similar to the long-interval speech-spectrum which is being masked." Miller, G. A. (1963). Language and communication. New York: McGraw-Hill. How this is accomplished inside the Digital Signal Process of the generator is critical to the success of the process.